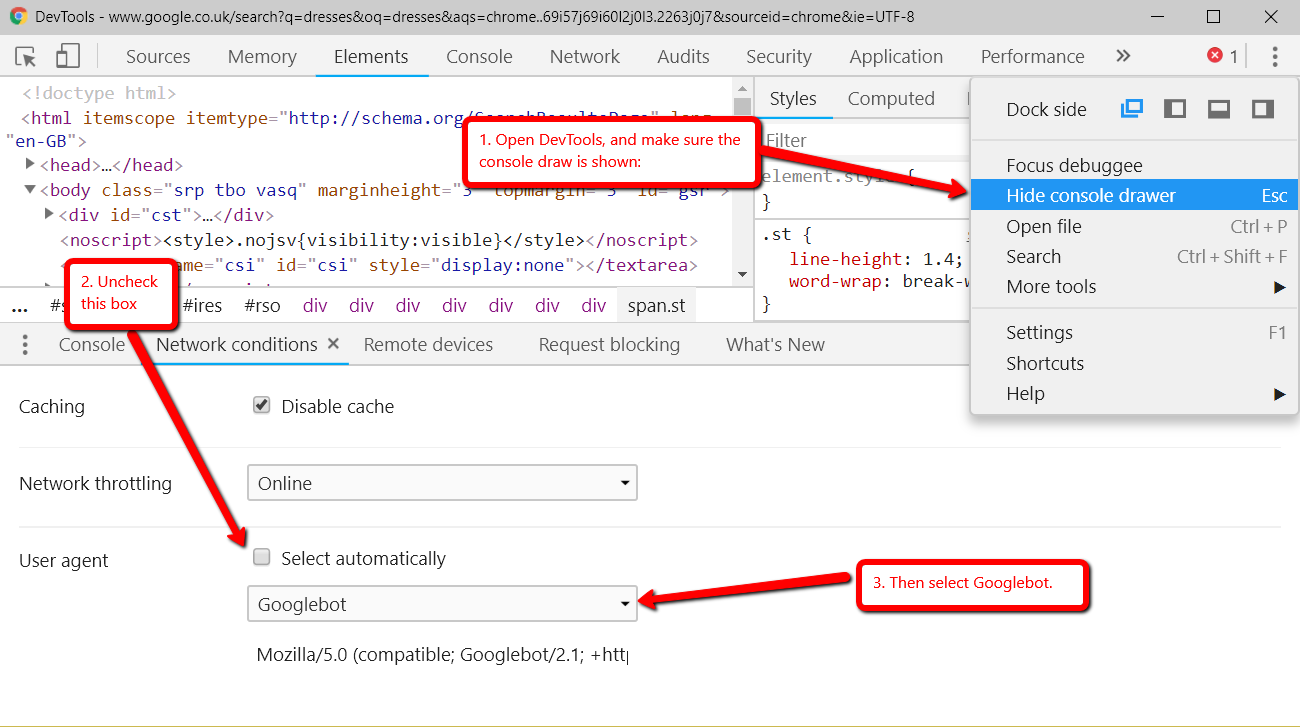
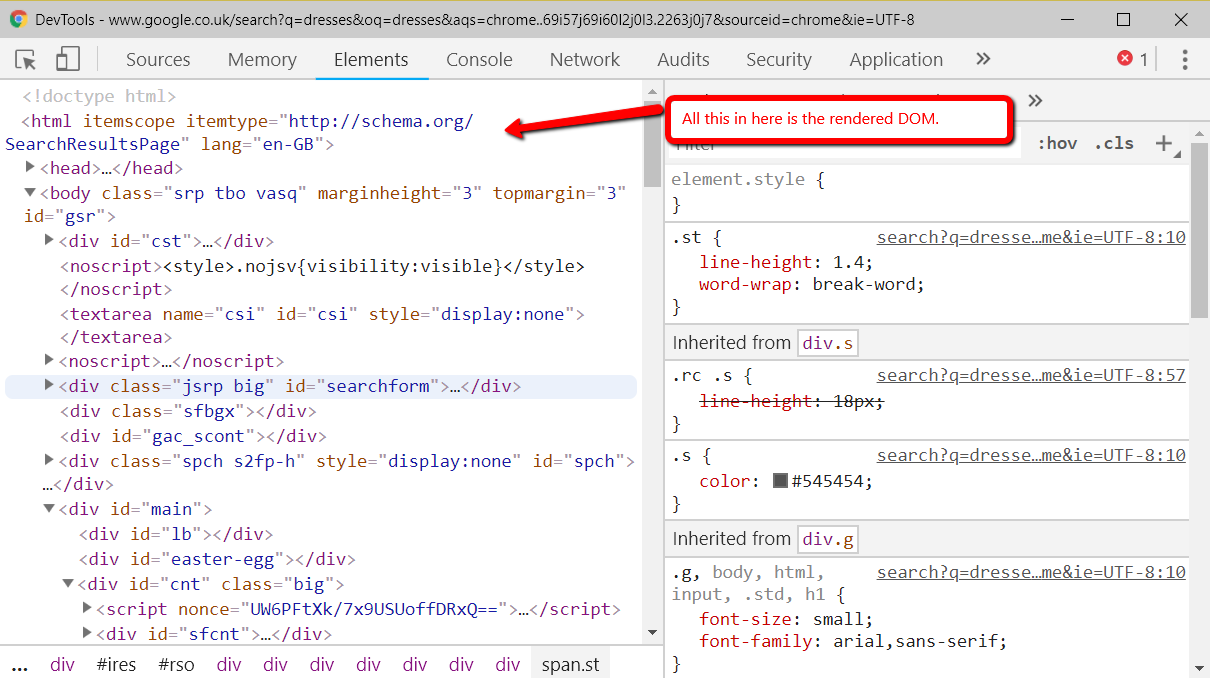
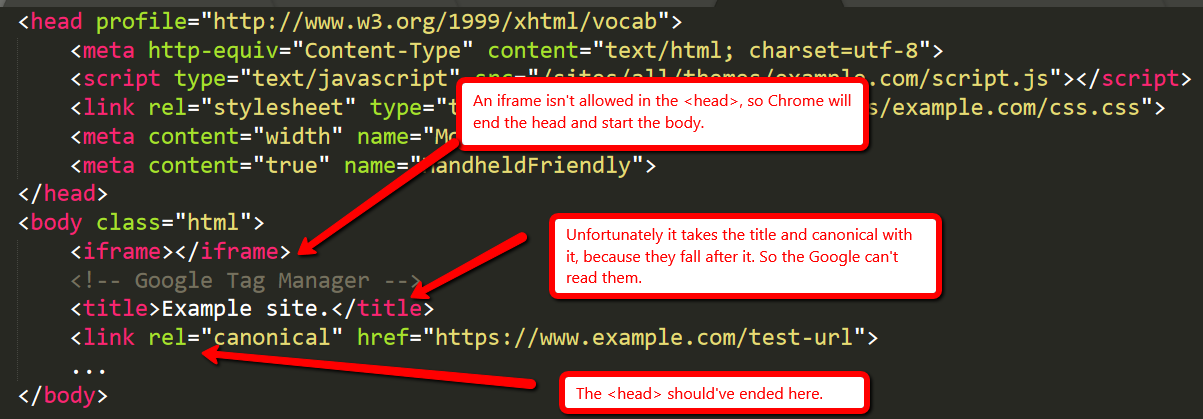
Posted by Carlosesal
There is no doubt that Google Analytics is one of the most important tools you could use to understand your users’ behavior and measure the performance of your site. There’s a reason it’s used by millions across the world.
But despite being such an essential part of the decision-making process for many businesses and blogs, I often find sites (of all sizes) that do little or no data filtering after installing the tracking code, which is a huge mistake.
Think of a Google Analytics property without filtered data as one of those styrofoam cakes with edible parts. It may seem genuine from the top, and it may even feel right when you cut a slice, but as you go deeper and deeper you find that much of it is artificial.

If you’re one of those that haven’t properly configured their Google Analytics and you only pay attention to the summary reports, you probably won’t notice that there’s all sorts of bogus information mixed in with your real user data.
And as a consequence, you won’t realize that your efforts are being wasted on analyzing data that doesn’t represent the actual performance of your site.
To make sure you’re getting only the real ingredients and prevent you from eating that slice of styrofoam, I’ll show you how to use the tools that GA provides to eliminate all the artificial excess that inflates your reports and corrupts your data.
Common Google Analytics threats
As most of the people I’ve worked with know, I’ve always been obsessed with the accuracy of data, mainly because as a marketer/analyst there’s nothing worse than realizing that you’ve made a wrong decision because your data wasn’t accurate. That’s why I’m continually exploring new ways of improving it.

As a result of that research, I wrote my first Moz post about the importance of filtering in Analytics, specifically about ghost spam, which was a significant problem at that time and still is (although to a lesser extent).
While the methods described there are still quite useful, I’ve since been researching solutions for other types of Google Analytics spam and a few other threats that might not be as annoying, but that are equally or even more harmful to your Analytics.
Let’s review, one by one.
Ghosts, crawlers, and other types of spam
The GA team has done a pretty good job handling ghost spam. The amount of it has been dramatically reduced over the last year, compared to the outbreak in 2015/2017.
However, the millions of current users and the thousands of new, unaware users that join every day, plus the majority’s curiosity to discover why someone is linking to their site, make Google Analytics too attractive a target for the spammers to just leave it alone.
The same logic can be applied to any widely used tool: no matter what security measures it has, there will always be people trying to abuse its reach for their own interest. Thus, it’s wise to add an extra security layer.
Take, for example, the most popular CMS: Wordpress. Despite having some built-in security measures, if you don’t take additional steps to protect it (like setting a strong username and password or installing a security plugin), you run the risk of being hacked.
The same happens to Google Analytics, but instead of plugins, you use filters to protect it.
In which reports can you look for spam?
Spam traffic will usually show as a Referral, but it can appear in any part of your reports, even in unsuspecting places like a language or page title.
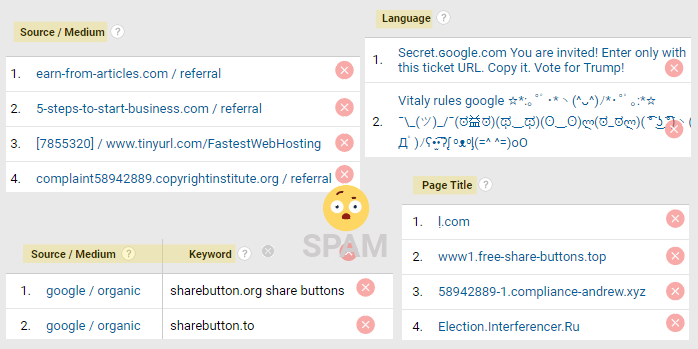
Sometimes spammers will try to fool by using misleading URLs that are very similar to known websites, or they may try to get your attention by using unusual characters and emojis in the source name.

Independently of the type of spam, there are 3 things you always should do when you think you found one in your reports:

- Never visit the suspicious URL. Most of the time they’ll try to sell you something or promote their service, but some spammers might have some malicious scripts on their site.
- This goes without saying, but never install scripts from unknown sites; if for some reason you did, remove it immediately and scan your site for malware.
- Filter out the spam in your Google Analytics to keep your data clean (more on that below).
If you’re not sure whether an entry on your report is real, try searching for the URL in quotes (“example.com”). Your browser won’t open the site, but instead will show you the search results; if it is spam, you’ll usually see posts or forums complaining about it.
If you still can’t find information about that particular entry, give me a shout — I might have some knowledge for you.
Bot traffic
A bot is a piece of software that runs automated scripts over the Internet for different purposes.
There are all kinds of bots. Some have good intentions, like the bots used to check copyrighted content or the ones that index your site for search engines, and others not so much, like the ones scraping your content to clone it.
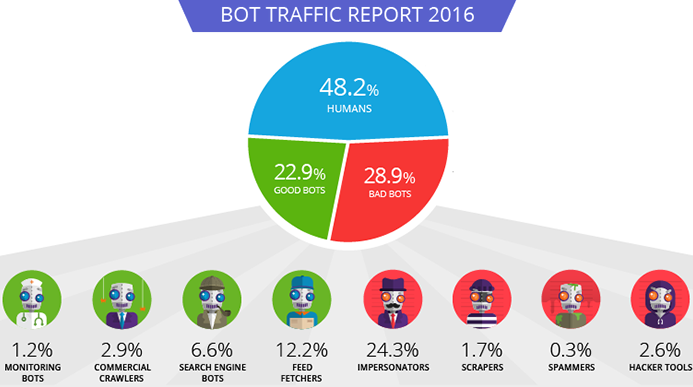
2016 bot traffic report. Source: Incapsula
In either case, this type of traffic is not useful for your reporting and might be even more damaging than spam both because of the amount and because it’s harder to identify (and therefore to filter it out).
It’s worth mentioning that bots can be blocked from your server to stop them from accessing your site completely, but this usually involves editing sensible files that require high technical knowledge, and as I said before, there are good bots too.
So, unless you’re receiving a direct attack that’s skewing your resources, I recommend you just filter them in Google Analytics.
In which reports can you look for bot traffic?
Bots will usually show as Direct traffic in Google Analytics, so you’ll need to look for patterns in other dimensions to be able to filter it out. For example, large companies that use bots to navigate the Internet will usually have a unique service provider.
I’ll go into more detail on this below.
Internal traffic
Most users get worried and anxious about spam, which is normal — nobody likes weird URLs showing up in their reports. However, spam isn’t the biggest threat to your Google Analytics.
You are!
The traffic generated by people (and bots) working on the site is often overlooked despite the huge negative impact it has. The main reason it’s so damaging is that in contrast to spam, internal traffic is difficult to identify once it hits your Analytics, and it can easily get mixed in with your real user data.
There are different types of internal traffic and different ways of dealing with it.
Direct internal traffic
Testers, developers, marketing team, support, outsourcing… the list goes on. Any member of the team that visits the company website or blog for any purpose could be contributing.
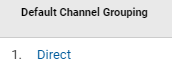
In which reports can you look for direct internal traffic?
Unless your company uses a private ISP domain, this traffic is tough to identify once it hits you, and will usually show as Direct in Google Analytics.
Third-party sites/tools
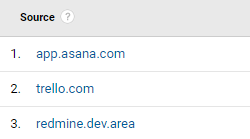
This type of internal traffic includes traffic generated directly by you or your team when using tools to work on the site; for example, management tools like Trello or Asana,
It also considers traffic coming from bots doing automatic work for you; for example, services used to monitor the performance of your site, like Pingdom or GTmetrix.

Some types of tools you should consider:
- Project management
- Social media management
- Performance/uptime monitoring services
- SEO tools
In which reports can you look for internal third-party tools traffic?
This traffic will usually show as Referral in Google Analytics.
Development/staging environments
Some websites use a test environment to make changes before applying them to the main site. Normally, these staging environments have the same tracking code as the production site, so if you don’t filter it out, all the testing will be recorded in Google Analytics.
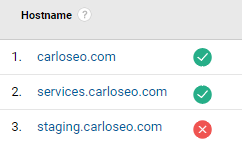
In which reports can you look for development/staging environments?
This traffic will usually show as Direct in Google Analytics, but you can find it under its own hostname (more on this later).
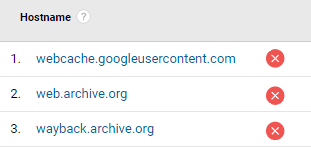
Web archive sites and cache services
Archive sites like the Wayback Machine offer historical views of websites. The reason you can see those visits on your Analytics — even if they are not hosted on your site — is that the tracking code was installed on your site when the Wayback Machine bot copied your content to its archive.

One thing is for certain: when someone goes to check how your site looked in 2015, they don’t have any intention of buying anything from your site — they’re simply doing it out of curiosity, so this traffic is not useful.
In which reports can you look for traffic from web archive sites and cache services?
You can also identify this traffic on the hostname report.
A basic understanding of filters
The solutions described below use Google Analytics filters, so to avoid problems and confusion, you’ll need some basic understanding of how they work and check some prerequisites.
Things to consider before using filters:
1. Create an unfiltered view.
Before you do anything, it’s highly recommendable to make an unfiltered view; it will help you track the efficacy of your filters. Plus, it works as a backup in case something goes wrong.
2. Make sure you have the correct permissions.
You will need edit permissions at the account level to create filters; edit permissions at view or property level won’t work.
3. Filters don’t work retroactively.
In GA, aggregated historical data can’t be deleted, at least not permanently. That’s why the sooner you apply the filters to your data, the better.
4. The changes made by filters are permanent!
If your filter is not correctly configured because you didn’t enter the correct expression (missing relevant entries, a typo, an extra space, etc.), you run the risk of losing valuable data FOREVER; there is no way of recovering filtered data.
But don’t worry — if you follow the recommendations below, you shouldn’t have a problem.
5. Wait for it.
Most of the time you can see the effect of the filter within minutes or even seconds after applying it; however, officially it can take up to twenty-four hours, so be patient.
Types of filters
There are two main types of filters: predefined and custom.
Predefined filters are very limited, so I rarely use them. I prefer to use the custom ones because they allow regular expressions, which makes them a lot more flexible.
Within the custom filters, there are five types: exclude, include, lowercase/uppercase, search and replace, and advanced.
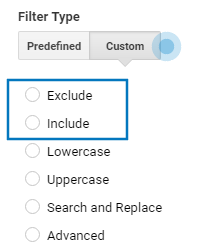
Here we will use the first two: exclude and include. We’ll save the rest for another occasion.
Essentials of regular expressions
If you already know how to work with regular expressions, you can jump to the next section.
REGEX (short for regular expressions) are text strings prepared to match patterns with the use of some special characters. These characters help match multiple entries in a single filter.
Don’t worry if you don’t know anything about them. We will use only the basics, and for some filters, you will just have to COPY-PASTE the expressions I pre-built.
REGEX special characters
There are many special characters in REGEX, but for basic GA expressions we can focus on three:
- ^ The caret: used to indicate the beginning of a pattern,
- $ The dollar sign: used to indicate the end of a pattern,
- | The pipe or bar: means “OR,” and it is used to indicate that you are starting a new pattern.

When using the pipe character, you should never ever:
- Put it at the beginning of the expression,
- Put it at the end of the expression,
- Put 2 or more together.
Any of those will mess up your filter and probably your Analytics.
A simple example of REGEX usage
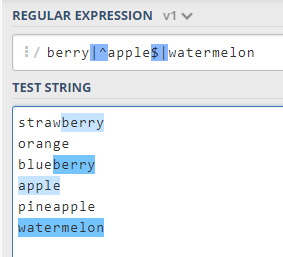
Let’s say I go to a restaurant that has an automatic machine that makes fruit salad, and to choose the fruit, you should use regular xxpressions.
This super machine has the following fruits to choose from: strawberry, orange, blueberry, apple, pineapple, and watermelon.
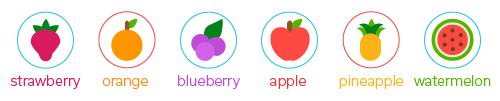
To make a salad with my favorite fruits (strawberry, blueberry, apple, and watermelon), I have to create a REGEX that matches all of them. Easy! Since the pipe character “|” means OR I could do this:
- REGEX 1: strawberry|blueberry|apple|watermelon
The problem with that expression is that REGEX also considers partial matches, and since pineapple also contains “apple,” it would be selected as well… and I don’t like pineapple!
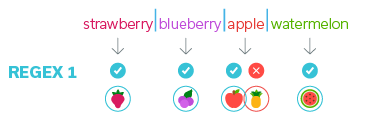
To avoid that, I can use the other two special characters I mentioned before to make an exact match for apple. The caret “^” (begins here) and the dollar sign “$” (ends here). It will look like this:
- REGEX 2: strawberry|blueberry|^apple$|watermelon
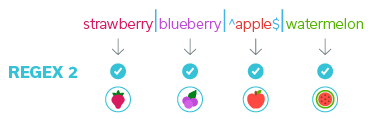
The expression will select precisely the fruits I want.
But let’s say for demonstration’s sake that the fewer characters you use, the cheaper the salad will be. To optimize the expression, I can use the ability for partial matches in REGEX.
Since strawberry and blueberry both contain “berry,” and no other fruit in the list does, I can rewrite my expression like this:
- Optimized REGEX: berry|^apple$|watermelon
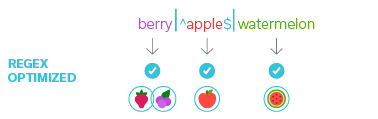
That’s it — now I can get my fruit salad with the right ingredients, and at a lower price.
3 ways of testing your filter expression
As I mentioned before, filter changes are permanent, so you have to make sure your filters and REGEX are correct. There are 3 ways of testing them:
- Right from the filter window; just click on “Verify this filter,” quick and easy. However, it’s not the most accurate since it only takes a small sample of data.
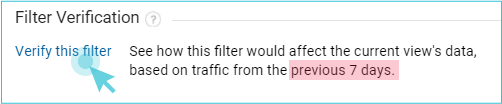
- Using an online REGEX tester; very accurate and colorful, you can also learn a lot from these, since they show you exactly the matching parts and give you a brief explanation of why.
- Using an in-table temporary filter in GA; you can test your filter against all your historical data. This is the most precise way of making sure you don’t miss anything.
If you’re doing a simple filter or you have plenty of experience, you can use the built-in filter verification. However, if you want to be 100% sure that your REGEX is ok, I recommend you build the expression on the online tester and then recheck it using an in-table filter.
Quick REGEX challenge
Here’s a small exercise to get you started. Go to this premade example with the optimized expression from the fruit salad case and test the first 2 REGEX I made. You’ll see live how the expressions impact the list.
Now make your own expression to pay as little as possible for the salad.
Remember:
- We only want strawberry, blueberry, apple, and watermelon;
- The fewer characters you use, the less you pay;
- You can do small partial matches, as long as they don’t include the forbidden fruits.
Tip: You can do it with as few as 6 characters.
Now that you know the basics of REGEX, we can continue with the filters below. But I encourage you to put “learn more about REGEX” on your to-do list — they can be incredibly useful not only for GA, but for many tools that allow them.
How to create filters to stop spam, bots, and internal traffic in Google Analytics
Back to our main event: the filters!
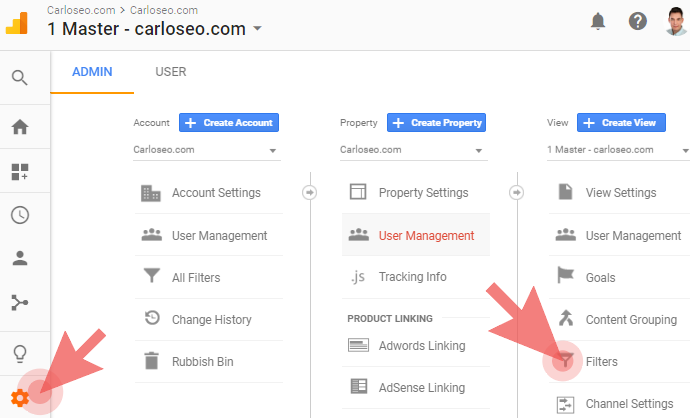
Where to start: To avoid being repetitive when describing the filters below, here are the standard steps you need to follow to create them:
- Go to the admin section in your Google Analytics (the gear icon at the bottom left corner),
- Under the View column (master view), click the button “Filters” (don’t click on “All filters“ in the Account column):
- Click the red button “+Add Filter” (if you don’t see it or you can only apply/remove already created filters, then you don’t have edit permissions at the account level. Ask your admin to create them or give you the permissions.):

- Then follow the specific configuration for each of the filters below.
The filter window is your best partner for improving the quality of your Analytics data, so it will be a good idea to get familiar with it.
Valid hostname filter (ghost spam, dev environments)
Prevents traffic from:
- Ghost spam
- Development hostnames
- Scraping sites
- Cache and archive sites
This filter may be the single most effective solution against spam. In contrast with other commonly shared solutions, the hostname filter is preventative, and it rarely needs to be updated.
Ghost spam earns its name because it never really visits your site. It’s sent directly to the Google Analytics servers using a feature called Measurement Protocol, a tool that under normal circumstances allows tracking from devices that you wouldn’t imagine that could be traced, like coffee machines or refrigerators.

Real users pass through your server, then the data is sent to GA; hence it leaves valid information. Ghost spam is sent directly to GA servers, without knowing your site URL; therefore all data left is fake. Source: carloseo.com
The spammer abuses this feature to simulate visits to your site, most likely using automated scripts to send traffic to randomly generated tracking codes (UA-0000000-1).
Since these hits are random, the spammers don’t know who they’re hitting; for that reason ghost spam will always leave a fake or (not set) host. Using that logic, by creating a filter that only includes valid hostnames all ghost spam will be left out.
Where to find your hostnames
Now here comes the “tricky” part. To create this filter, you will need, to make a list of your valid hostnames.
A list of what!?
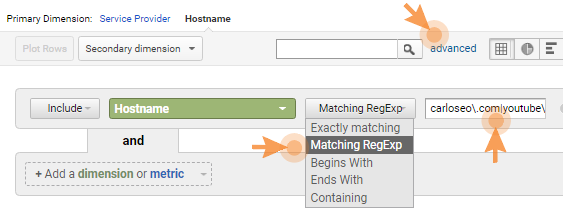
Essentially, a hostname is any place where your GA tracking code is present. You can get this information from the hostname report:
- Go to Audience > Select Network > At the top of the table change the primary dimension to Hostname.
If your Analytics is active, you should see at least one: your domain name. If you see more, scan through them and make a list of all the ones that are valid for you.
Types of hostname you can find
The good ones:
|
Type
|
Example
|
|---|
|
Your domain and subdomains
|
yourdomain.com
|
|
Tools connected to your Analytics
|
YouTube, MailChimp
|
|
Payment gateways
|
Shopify, booking systems
|
|
Translation services
|
Google Translate
|
|
Mobile speed-up services
|
Google weblight
|
The bad ones (by bad, I mean not useful for your reports):
Type
| Example/Description
|
|---|
Staging/development environments
| staging.yourdomain.com
|
Internet archive sites
| web.archive.org
|
Scraping sites that don’t bother to trim the content
| The URL of the scraper
|
Spam
| Most of the time they will show their URL, but sometimes they may use the name of a known website to try to fool you. If you see a URL that you don’t recognize, just think, “do I manage it?” If the answer is no, then it isn’t your hostname.
|
(not set) hostname
| It usually comes from spam. On rare occasions it’s related to tracking code issues.
|
Below is an example of my hostname report. From the unfiltered view, of course, the master view is squeaky clean.
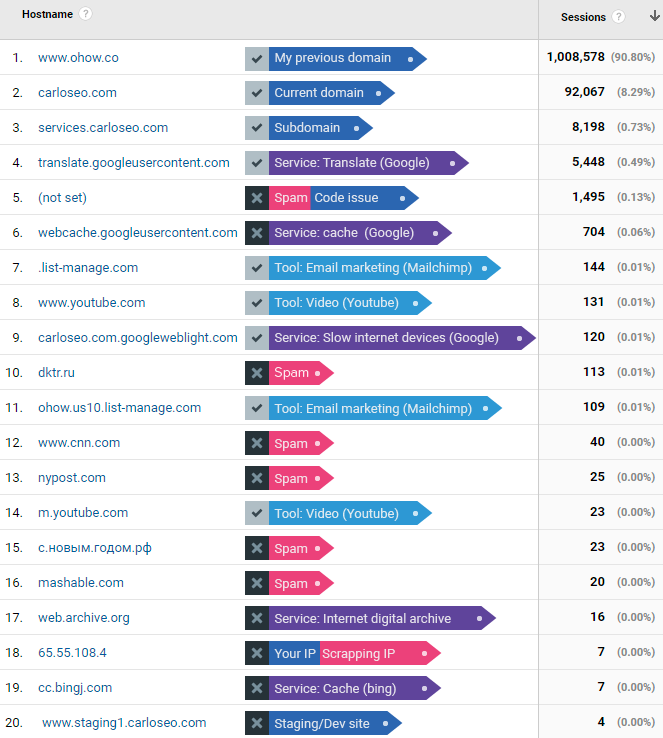
Now with the list of your good hostnames, make a regular expression. If you only have your domain, then that is your expression; if you have more, create an expression with all of them as we did in the fruit salad example:
Hostname REGEX (example)
yourdomain.com|hostname2|hostname3|hostname4
Important! You cannot create more than one “Include hostname filter”; if you do, you will exclude all data. So try to fit all your hostnames into one expression (you have 255 characters).
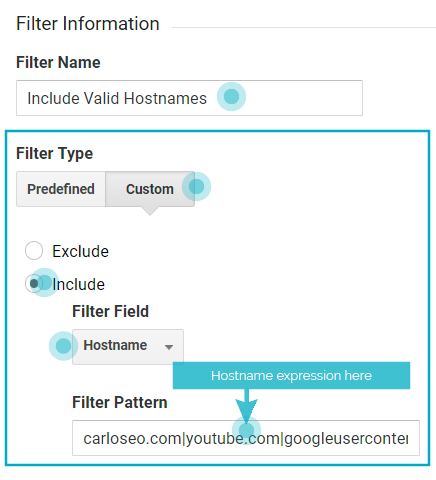
The “valid hostname filter” configuration:
- Filter Name: Include valid hostnames
- Filter Type: Custom > Include
- Filter Field: Hostname
- Filter Pattern: [hostname REGEX you created]
Campaign source filter (Crawler spam, internal sources)
Prevents traffic from:
- Crawler spam
- Internal third-party tools (Trello, Asana, Pingdom)
Important note: Even if these hits are shown as a referral, the field you should use in the filter is “Campaign source” — the field “Referral” won’t work.
Filter for crawler spam
The second most common type of spam is crawler. They also pretend to be a valid visit by leaving a fake source URL, but in contrast with ghost spam, these do access your site. Therefore, they leave a correct hostname.
You will need to create an expression the same way as the hostname filter, but this time, you will put together the source/URLs of the spammy traffic. The difference is that you can create multiple exclude filters.
Crawler REGEX (example)
spam1|spam2|spam3|spam4
Crawler REGEX (pre-built)
As I promised, here are latest pre-built crawler expressions that you just need to copy/paste.

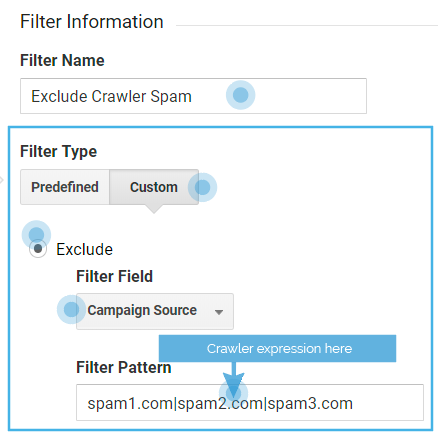
The “crawler spam filter” configuration:
- Filter Name: Exclude crawler spam 1
- Filter Type: Custom > Exclude
- Filter Field: Campaign source
- Filter Pattern: [crawler REGEX]
Filter for internal third-party tools
Although you can combine your crawler spam filter with internal third-party tools, I like to have them separated, to keep them organized and more accessible for updates.
The “internal tools filter” configuration:
- Filter Name: Exclude internal tool sources
- Filter Pattern: [tool source REGEX]
Internal Tools REGEX (example)
trello|asana|redmine

In case, that one of the tools that you use internally also sends you traffic from real visitors, don’t filter it. Instead, use the “Exclude Internal URL Query” below.
For example, I use Trello, but since I share analytics guides on my site, some people link them from their Trello accounts.
Filters for language spam and other types of spam
The previous two filters will stop most of the spam; however, some spammers use different methods to bypass the previous solutions.
For example, they try to confuse you by showing one of your valid hostnames combined with a well-known source like Apple, Google, or Moz. Even my site has been a target (not saying that everyone knows my site; it just looks like the spammers don’t agree with my guides).
However, even if the source and host look fine, the spammer injects their message in another part of your reports like the keyword, page title, and even as a language.
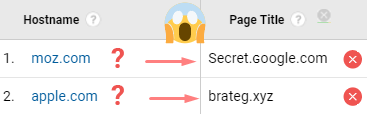
In those cases, you will have to take the dimension/report where you find the spam and choose that name in the filter. It’s important to consider that the name of the report doesn’t always match the name in the filter field:
|
Report name
|
Filter field
|
|---|
|
Language
|
Language settings
|
|
Referral
|
Campaign source
|
|
Organic Keyword
|
Search term
|
|
Service Provider
|
ISP Organization
|
|
Network Domain
|
ISP Domain
|
Here are a couple of examples.
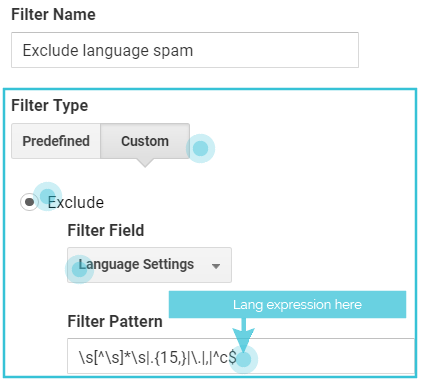
The “language spam/bot filter” configuration:
- Filter Name: Exclude language spam
- Filter Type: Custom > Exclude
- Filter Field: Language settings
- Filter Pattern: [Language REGEX]
Language Spam REGEX (Prebuilt)
\s[^\s]*\s|.{15,}|\.|,|^c$
The expression above excludes fake languages that don’t meet the required format. For example, take these weird messages appearing instead of regular languages like en-us or es-es:
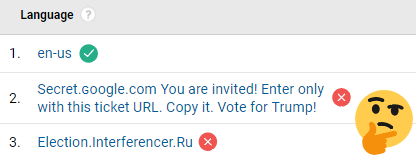
Examples of language spam
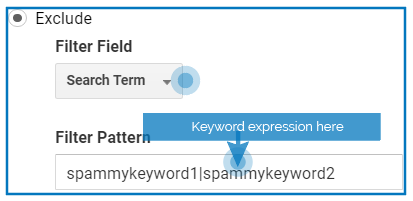
The organic/keyword spam filter configuration:
- Filter Name: Exclude organic spam
- Filter Type: Custom > Exclude
- Filter Field: Search term
- Filter Pattern: [keyword REGEX]
Filters for direct bot traffic
Bot traffic is a little trickier to filter because it doesn’t leave a source like spam, but it can still be filtered with a bit of patience.
The first thing you should do is enable bot filtering. In my opinion, it should be enabled by default.
Go to the Admin section of your Analytics and click on View Settings. You will find the option “Exclude all hits from known bots and spiders” below the currency selector:

It would be wonderful if this would take care of every bot — a dream come true. However, there’s a catch: the key here is the word “known.” This option only takes care of known bots included in the “IAB known bots and spiders list.” That’s a good start, but far from enough.
There are a lot of “unknown” bots out there that are not included in that list, so you’ll have to play detective and search for patterns of direct bot traffic through different reports until you find something that can be safely filtered without risking your real user data.

To start your bot trail search, click on the Segment box at the top of any report, and select the “Direct traffic” segment.
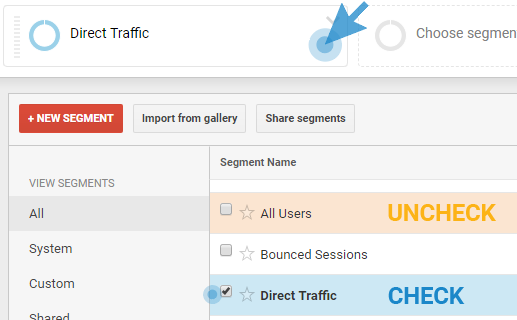
Then navigate through different reports to see if you find anything suspicious.
Some reports to start with:
- Service provider
- Browser version
- Network domain
- Screen resolution
- Flash version
- Country/City
Signs of bot traffic
Although bots are hard to detect, there are some signals you can follow:
- An unnatural increase of direct traffic
- Old versions (browsers, OS, Flash)
- They visit the home page only (usually represented by a slash “/” in GA)
- Extreme metrics:
- Bounce rate close to 100%,
- Session time close to 0 seconds,
- 1 page per session,
- 100% new users.
Important! If you find traffic that checks off many of these signals, it is likely bot traffic. However, not all entries with these characteristics are bots, and not all bots match these patterns, so be cautious.
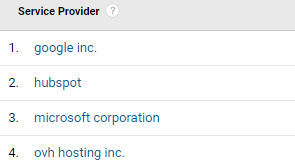
Perhaps the most useful report that has helped me identify bot traffic is the “Service Provider” report. Large corporations frequently use their own Internet service provider name.
I also have a pre-built expression for ISP bots, similar to the crawler expressions.
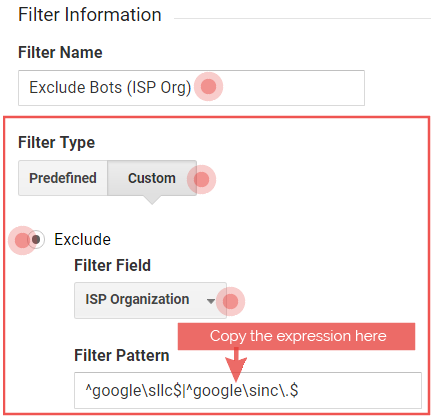
The bot ISP filter configuration:
- Filter Name: Exclude bots by ISP
- Filter Type: Custom > Exclude
- Filter Field: ISP organization
- Filter Pattern: [ISP provider REGEX]
ISP provider bots REGEX (prebuilt)
hubspot|^google\sllc$|^google\sinc\.$|alibaba\.com\sllc|ovh\shosting\sinc\.
Latest ISP bot expression
IP filter for internal traffic
We already covered different types of internal traffic, the one from test sites (with the hostname filter), and the one from third-party tools (with the campaign source filter).
Now it’s time to look at the most common and damaging of all: the traffic generated directly by you or any member of your team while working on any task for the site.
To deal with this, the standard solution is to create a filter that excludes the public IP (not private) of all locations used to work on the site.
Examples of places/people that should be filtered
- Office
- Support
- Home
- Developers
- Hotel
- Coffee shop
- Bar
- Mall
- Any place that is regularly used to work on your site
To find the public IP of the location you are working at, simply search for “my IP” in Google. You will see one of these versions:
IP version
| Example
|
|---|
Short IPv4
| 1.23.45.678
|
Long IPv6
| 2001:0db8:85a3:0000:0000:8a2e:0370:7334
|
No matter which version you see, make a list with the IP of each place and put them together with a REGEX, the same way we did with other filters.
- IP address expression: IP1|IP2|IP3|IP4 and so on.
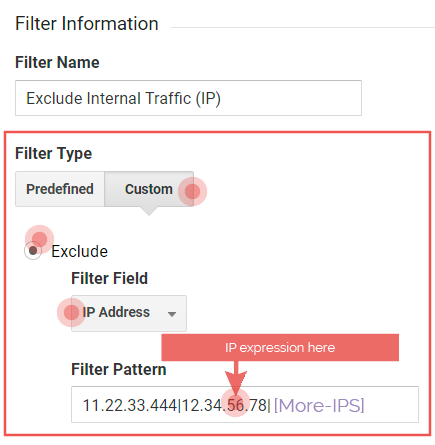
The static IP filter configuration:
- Filter Name: Exclude internal traffic (IP)
- Filter Type: Custom > Exclude
- Filter Field: IP Address
- Filter Pattern: [The IP expression]
Cases when this filter won’t be optimal:
There are some cases in which the IP filter won’t be as efficient as it used to be:
- You use IP anonymization (required by the GDPR regulation). When you anonymize the IP in GA, the last part of the IP is changed to 0. This means that if you have 1.23.45.678, GA will pass it as 1.23.45.0, so you need to put it like that in your filter. The problem is that you might be excluding other IPs that are not yours.
- Your Internet provider changes your IP frequently (Dynamic IP). This has become a common issue lately, especially if you have the long version (IPv6).
- Your team works from multiple locations. The way of working is changing — now, not all companies operate from a central office. It’s often the case that some will work from home, others from the train, in a coffee shop, etc. You can still filter those places; however, maintaining the list of IPs to exclude can be a nightmare,
- You or your team travel frequently. Similar to the previous scenario, if you or your team travels constantly, there’s no way you can keep up with the IP filters.
If you check one or more of these scenarios, then this filter is not optimal for you; I recommend you to try the “Advanced internal URL query filter” below.
URL query filter for internal traffic
If there are dozens or hundreds of employees in the company, it’s extremely difficult to exclude them when they’re traveling, accessing the site from their personal locations, or mobile networks.
Here’s where the URL query comes to the rescue. To use this filter you just need to add a query parameter. I add “?internal” to any link your team uses to access your site:
- Internal newsletters
- Management tools (Trello, Redmine)
- Emails to colleagues
- Also works by directly adding it in the browser address bar
Basic internal URL query filter
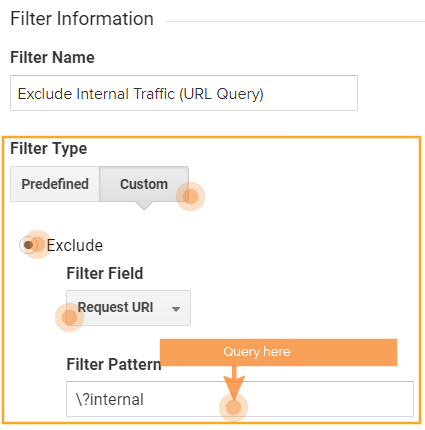
The basic version of this solution is to create a filter to exclude any URL that contains the query “?internal”.
- Filter Name: Exclude Internal Traffic (URL Query)
- Filter Type: Custom > Exclude
- Filter Field: Request URI
- Filter Pattern: \?internal
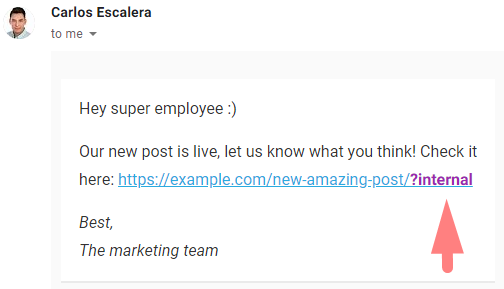
This solution is perfect for instances were the user will most likely stay on the landing page, for example, when sending a newsletter to all employees to check a new post.
If the user will likely visit more than the landing page, then the subsequent pages will be recorded.
Advanced internal URL query filter
This solution is the champion of all internal traffic filters!
It’s a more comprehensive version of the previous solution and works by filtering internal traffic dynamically using Google Tag Manager, a GA custom dimension, and cookies.

Although this solution is a bit more complicated to set up, once it’s in place:
- It doesn’t need maintenance
- Any team member can use it, no need to explain techy stuff
- Can be used from any location
- Can be used from any device, and any browser
To activate the filter, you just have to add the text “?internal” to any URL of the website.
That will insert a small cookie in the browser that will tell GA not to record the visits from that browser.
And the best of it is that the cookie will stay there for a year (unless it is manually removed), so the user doesn’t have to add “?internal” every time.
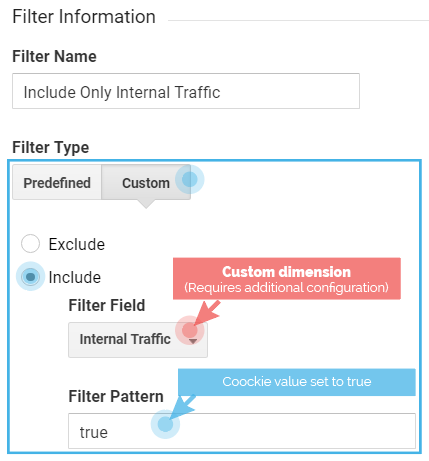
Bonus filter: Include only internal traffic
In some occasions, it’s interesting to know the traffic generated internally by employees — maybe because you want to measure the success of an internal campaign or just because you’re a curious person.
In that case, you should create an additional view, call it “Internal Traffic Only,” and use one of the internal filters above. Just one! Because if you have multiple include filters, the hit will need to match all of them to be counted.
If you configured the “Advanced internal URL query” filter, use that one. If not, choose one of the others.
The configuration is exactly the same — you only need to change “Exclude” for “Include.”
Cleaning historical data
The filters will prevent future hits from junk traffic.
But what about past affected data?
I know I told you that deleting aggregated historical data is not possible in GA. However, there’s still a way to temporarily clean up at least some of the nasty traffic that has already polluted your reports.
For this, we’ll use an advanced segment (a subset of your Analytics data). There are built-in segments like “Organic” or “Mobile,” but you can also build one using your own set of rules.
To clean our historical data, we will build a segment using all the expressions from the filters above as conditions (except the ones from the IP filter, because IPs are not stored in GA; hence, they can’t be segmented).
To help you get started, you can import this segment template.
You just need to follow the instructions on that page and replace the placeholders. Here is how it looks:
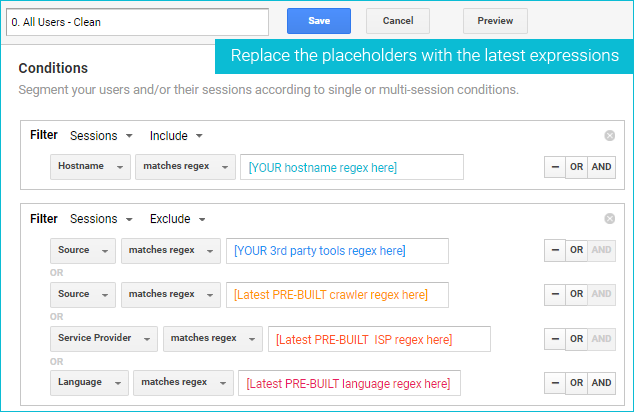
In the actual template, all text is black; the colors are just to help you visualize the conditions.
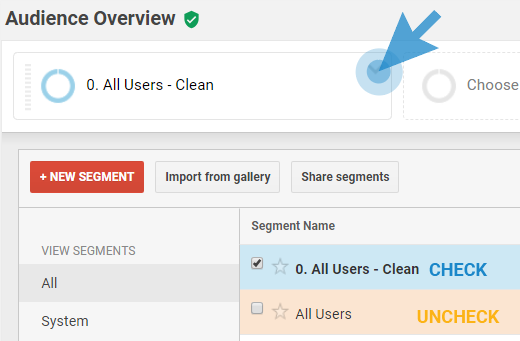
After importing it, to select the segment:
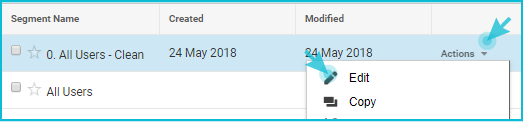
- Click on the box that says “All users” at the top of any of your reports
- From your list of segments, check the one that says “0. All Users – Clean”
- Lastly, uncheck the “All Users”
Now you can navigate through your reaports and all the junk traffic included in the segment will be removed.
A few things to consider when using this segment:
- Segments have to be selected each time. A way of having it selected by default is by adding a bookmark when the segment is selected.
- You can remove or add conditions if you need to.
- You can edit the segment at any time to update it or add conditions (open the list of segments, then click “Actions” then “Edit”).
- The hostname expression and third-party tools expression are different for each site.
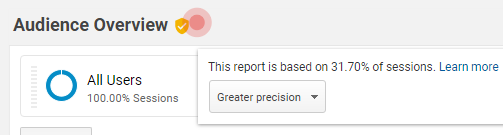
- If your site has a large volume of traffic, segments may sample your data when selected, so if you see the little shield icon at the top of your reports go yellow (normally is green), try choosing a shorter period (i.e. 1 year, 6 months, one month).
Conclusion: Which cake would you eat?
Having real and accurate data is essential for your Google Analytics to report as you would expect.
But if you haven’t filtered it properly, it’s almost certain that it will be filled with all sorts of junk and artificial information.
And the worst part is that if don’t realize that your reports contain bogus data, you will likely make wrong or poor decisions when deciding on the next steps for your site or business.

The filters I share above will help you prevent the three most harmful threats that are polluting your Google Analytics and don’t let you get a clear view of the actual performance of your site: spam, bots, and internal traffic.
Once these filters are in place, you can rest assured that your efforts (and money!) won’t be wasted on analyzing deceptive Google Analytics data, and your decisions will be based on solid information.
And the benefits don’t stop there. If you’re using other tools that import data from GA, for example, WordPress plugins like GADWP, excel add-ins like AnalyticsEdge, or SEO suites like Moz Pro, the benefits will trickle down to all of them as well.
Besides highlighting the importance of the filters in GA (which I hope I made clear by now), I would also love that for the preparation of these filters to give you the curiosity and basis to create others that will allow you to do all sorts of remarkable things with your data.
Remember, filters not only allow you to keep away junk, you can also use them to rearrange your real user information — but more on that on another occasion.
That’s it! I hope these tips help you make more sense of your data and make accurate decisions.
Have any questions, feedback, experiences? Let me know in the comments, or reach me on Twitter @carlosesal.
Complementary resources:
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
Continue reading →