SEO in the Personalization Age

Posted by gfiorelli1
- Driverless cars, paired with companies like Uber, will soon transport us about the city, offering us the extra time to revise our notes before an important business meeting.
- Leap-motion interfaces are available.
- Marketing has become personalized and targeted.
- We have experienced a loss of privacy in the name of a supposed greater safety.
In many respects, we can say that the future is (almost) now.
Of all the things that were presented in Minority Report, the one that most concerns us as SEOs and inbound marketers is the personalization of experiences that our potential customers have when looking for a product and/or information, when they share things online, and when they interact with our brands on our websites.
Search marketing and personalization
Personalization in search marketing is not something new—it was (re)launched on Google in 2005. Still, it was only with the launch of “Search, plus Your World” (January 2012), the rollout of the Venice Update (February 2012), and the introduction of Google Now (July 2012), that the personalization factor has become predominant.
If we ask everyday Google users about personalized search, though, this is what they answer:

This data from the excellent infographic on seotraininglondon.org reveals something that we might have guessed in talking about rankings with our clients: the average user does not know that their Google SERPs are personalized.
To tell the truth, we SEOs also tend to forget that search is almost always personalized, and we examine concepts such as, for example, neutral search.
For example, we tend to act this way when we try to understand the rankings of our sites or when we do competitive analyses. It is certainly not incorrect—it is a necessary starting point—but in reality, it is not enough anymore.
Take the case where our site is national or global: In that case, the personalization of the search experience is such that we should not only check how our site ranks in the U.S. or the UK, but we should also in smaller geographic areas of our targeted country.
At the same time, we should see who our competitors are with a “micro-geographic” focus. In fact, while we might be on the first page in a totally neutral search with its geographical center being the political capital of the country we are analyzing, maybe we don’t rank so highly in the searches done in a city that we consider a target as important as the “nation” (i.e. Seattle or Manchester).
Why? Because the often shamefully forgotten Venice Update enhances the localization of the user performing a search in terms of how their SERPs are shaped. Hence, local businesses, which might not be relevant on a national/global scale, are indeed relevant locally. In those cases, they can be shown at the expense of “national” or “global” sites, which often do not possess sufficient relevance at a local level.
And that’s personalization (note: in the concept of personalization I personally include context, because without it, personalization would provide a poor search experience).
But that’s not the only way localization influences the personalization of search.
In fact, as both Tom Anthony and Will Critchlow explained well, localization (and other contextual information) is a key component of what they defined as “new queries,” which include both a explicit and implicit aspect.
An even stronger implementation of personalization is possible: implicit-only queries, as they are defined by Baris Gultekin in this video interview shot at Google I/O 2013.
These queries are those that users don’t even actually perform, but that Google predicts they are implicitly performing. The results are shown in Google Now cards:

In the first case (personalization due to geolocalization), we can try to acquire more relevance on a local level by creating events (online and/or offline), connections with local web sites, and partnerships with local influencers. Those influencers can be found with tools that geographically map social media followers/fans, such as Followerwonk (all the better if they are already connected with us):

Or, we can take advantage of the geographical segmentation of the people we have circled on Google Plus (and of the local communities’ pages, if they exist):

In the second case (“new queries” with implicit and explicit aspects), we can try to “enter” in the personalized SERPs of our users, creating content that is contextually relevant to a topic + location + device. For now, though, it is quite hard to determine how, from where, and for what a user is already searching on our own sites via Google search. This information can’t be easily understood with tools like Google Analytics, and Google Webmaster Tools does not offer us the opportunity to dig deeper than the country level. Hence, the best way to get this information is by actively obtaining feedback directly from our targeted audience.
In the third case (totally implicit queries), we can go with the classic SEO’s first reaction of fright and ask to have our site integrated in the Google Now ecosystem, as Zillow, Booking, Urbanspoon and many others have already done.
Personalization and Knowledge Base
Last May, at Google I/O 2013, Amit Singhal said, “The search of future will need to answer, converse, and anticipate.”

With “answer,” he refers to the Knowledge Graph, with “converse” to Voice Search, and finally with “anticipate” to Google Now. Knowledge Graph and Google Now are based mostly on the so-called Google Knowledge Base, and in both cases—as well as in Voice Search—semantics and entity recognition play an essential role.
Semantics, entity recognition and the Knowledge Base, then, are the foundation on which Google can really achieve the goal of creating its dreamed-of Star Trek computer, capable of providing information to the user by predicting its needs for information.
As I wrote in a previous post here on Moz, the Knowledge Base helps Google by answering how and why the documents are connected and searched, as well as an understanding of what named entities those same documents cite and are related to.
The most evident examples of this are the Knowledge Graph boxes:

This snapshot, though, shows another example of personalization.
Google presented me Saint Peter the Apostle because in a neutral search I performed before, Google agnostically presented me all the entities the Knowledge Graph could relate to the query “Saint Peter”.
As you can see, neutral “objective” searches still play a huge role in Google… but is this really so? No, it isn’t.
Even in a neutral search, personalization of search is present. Here are a couple of examples:

Knowledge Graph disambiguation boxes in Google.it neutral search for “San Pietro”

Knowledge Graph disambiguation boxes in Google.com neutral search for “San Pietro”

Knowledge Graph disambiguation boxes in Google.fr neutral search for “Saint Pierre”

Knowledge Graph disambiguation boxes in Google.com neutral search for “Saint Pierre”
Localization of the users—both geographically and linguistically—plays an evident role in the personalization of search.
But that’s not all. In fact—as I said before—personalization is always acting, not just when users are logged in. When you’re not signed in, Google uses a cookie to personalize your search experience based on past search information linked to your browser.
The more someone uses Google for search, even logged out, the more Google understands and refines the search experience for that user. Knowing that there are about 5,134,000,000 searches performed every day, we can understand how the Google Knowledge Base is endlessly updating itself. That is not Big Data, that’s Gigantic Data, all used for one purpose: to offer more personalized search and ad results.
How does Google personalize search?
Search History is surely the most important factor, but as we saw, localization has assumed an increasing relevance, especially because of the rise of mobile search.

Google seriously knows a lot about us. Crazypants! as a friend of mine would say.
How does search history shape the personalized SERPs, and how can Google strengthen the personalization of SERPs in relation to a query when search history is not present or is not sufficient by itself?
Google does this thanks to search entities, a concept that is explained in depth by Bill Slawski in this post.
Search entities, as described by Bill, are:
- A query a searcher submits
- Documents responsive to the query
- The search session during which the searcher submits the query
- The time at which the query is submitted
- Advertisements presented in response to the query
- Anchor text in a link in a document
- The domain associated with a document
The relationships between these search entities can create a “Probability Score,” which may determine if a web document is shown in a determined SERP or not.
I warmly suggest you read Bill’s post to find out more about all the possible relationships that can exist between these search entities, but for this post, I’d like to focus on these ones:
- The strength of relationships between these entities can be measured using a metric obtained from direct relationship strengths (derived from data indicating user behavior, such as user search history data) and indirect relationship strengths (derived from the direct relationship strengths).
- A relationship between a first entity that has insufficient support (e.g., not enough search history data) to associate a given property with the first entity and a second entity that does have sufficient support to associate the given property with the second entity can be identified, and the given property can be associated with the first entity with higher confidence.
Moreover, we could take advantage of the personalization of search thanks not only to being included in the personal search history of the users, but also to connections created with entities that are already in those users’ search history. This connection can be a link, a citation, or a co-occurrence in a document, which is considered more relevant than the query alone or the search history of the users.
Somehow this is not something new. In fact, when Richard Baxter talks about doing really targeted outreach, we know it is good from the point of view of being discovered by the audience. Creating content for other sites that are used by the people influencing our target market will often result in new users of our own site.
But now, this patent about search entities is evidence that typically inbound tactics can have a direct reflection on a purely search-related level.
Semantic web
When we talk about entities, we usually think about people, places, and things (i.e., a brand). But web documents are also entities.
And, in light of what is described in the patent cited above, the “probability score” of a web document, which can determine its presence in a SERP or its visibility in results for a determined query based on all the classic on-page “ranking factors,” can be improved by the use of structured data.
Structured data, from schema.org, Microdata and Open Graph, are important not just because they can gift our site’s search results with a rich snippet. That snippet is the facade of something more important: helping the search engines better understand what a document is all about.
For instance, the breadcrumb schema is surely important because it can help add mini-sitelinks to our snippets, but it is even more important because it clearly tells search engines how the documents in our site are hierarchically related between them.
Or, using an even better example, the article schema is the only way (or at least so it is described by Google) to obtain visibility in the In-Depth Articles search blend.
Therefore, the use of structured data has become essential, not only because rich snippets offer us a greater visibility in the SERPs, but also because not many people are using it (36.9% of URLs use Open Graph, and 9.9% use Schema.org, as reported by Matthew Brown at MozCon). In addition, structured data can help increase the relevance of a document for a determined query simply because it “helps our systems to better understand your website’s content, and improves the chances of it appearing in this new set of search results.”
The social layer
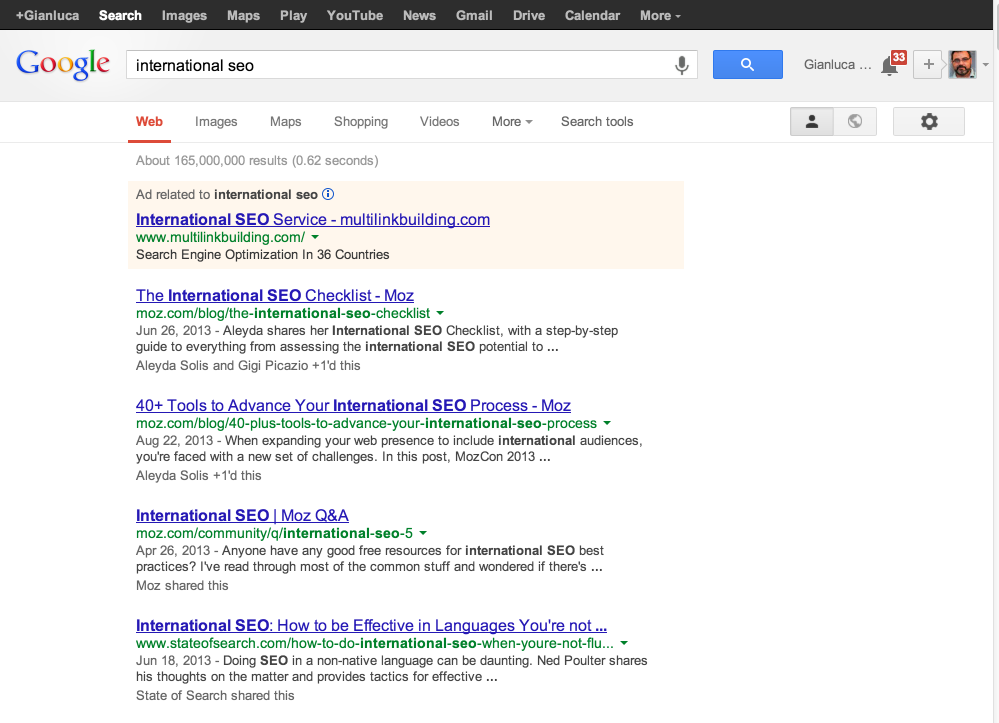
“Search, plus Your World” (SPYW), which de facto is how all logged in users use Google.com, can seriously help in outranking your competitors.
For instance, “The International SEO Checklist” by Aleyda on Moz ranks first for me and not third, because Aleyda and Gigi (and others in my Circles) plussed it. The “International SEO” Q&A page on Moz ranks third for me, simply because I have Moz circled. If it was not so, that page would not be present in the TOP 100, which we can see from a neutral search.
That means that, yes, in a personalized environment like SPYW, +1s have an impact in rankings, while that’s not the case in a neutral search.
Even if SPYW is not present outside of Google.com, plusses still play a prominent role in how SERPs are personalized. For instance, if I search for “International SEO” in Google.es, and I am logged in, by default Google is showing me search results from Aleyda’s posts, because they were all plussed by many people I’m circling on Google Plus. Instead, a neutral search in Google.es will show a completely different SERP.
The fact that we don’t have the option to switch to a neutral SERP in Google.es (or in the other regional versions of Google) means that all logged in users, if they are active on Google Plus, see an extremely personalized search result page.


The first snapshot presents a logged in personalized search in Google.es for “International SEO”. The second a neutral search. The influence of Google Plus in the first one is evident.
If we can find an evident social layer in search results, social media also has correlated values that can influence the personalization of the SERPs: branded keywords searches, prop-words, and an increase in search volume for our brand and related keywords.
In fact, we know that social media resides at the top of the funnel in the discovery phase. What we don’t realize is that social is also present in a post-discovery phase, when users are searching for confirmations to their conversion intentions.
If we are very active on social, and moreover if we are able to create authority via social media, if we do our homework, and—as SEOs—if we optimize how content is shared socially (SEOcial), then we can instill in our audience those keywords and topics for which they will search for us later on.
Email marketing and personalization
We can also influence the personalization of search with the integration of email marketing to our SEO activities.
We usually tend to consider email marketing just another channel—a very good one if performed correctly, because it can offer great conversion rates and huge amount of organic traffic, but we rarely think at it as a way to obtain visibility in search.
Now that is possible.
For totally implicit queries, we can mark up the emails we send to our users with schema.org for GMail.
The reminders we offer to our users will be presented as Google Now cards on mobile, but these annotations will also allow users to perform (voice) searches, which will deliver those same reminders created from the information we have marked up in our email.
For all the other kinds of queries, it is also possible to use email marketing in order to have visibility in the SERPs.
If you are a tester of the Gmail Search Field Trial (and use Google.com based in the US), you should see these enhanced results in your SERPs:

As you can easily tell, emails relevant to a user’s search can be shown in the SERPs.
This opens a completely new area of SEO activity, in which potential factors are:
- Who you email: If you email John Doe a lot, it’s likely that messages from John Doe are important.
- Which messages you open: Messages you open are likely to be more important than those you skip over.
- What keywords spark your interest: If you always read messages about soccer, a new message that contains those same soccer words is more likely to be important.
- Which messages you reply to: If you always reply to messages from your mom, messages she sends are likely to be important.
- Your recent use of stars, archive and delete: Messages you star are probably more important than messages you archive without opening.
I am not guessing these GMail ranking factors; I took them from this patent by MailRank now owned by Google.
Conclusions

Luckily Amit Singhal is present in this snapshot, or many of you would have started getting crazy with me.
Amit Singhal is right when he says that “Answer,” “Converse,” and “Anticipate”—deep personalization of search, I called it—is going to change search as we know it.
Is this maybe the reason why the Search Team at Google is now called the Knowledge Team? Is this maybe the main reason for “Not Provided” keywords, as Will Critchlow mentioned?
What I know is that personalization is already so heavily present in search that avoiding it in the name of a fading neutral search is not doing good SEO.
Moreover, personalized search is clearly telling us how SEO alone is not enough, but that content, social, and email marketing by themselves are also not enough to obtain a real and complete success in Internet marketing.
SEO, for instance, needs social to help people discover a site, just as social needs SEO to reward its activity with recurring conversions on the site.
Personalized search is pushing us to hasten the destruction of silos between Internet marketing disciplines, and hopefully it will oblige marketers to change and embrace a more holistic way of promoting a business online.
Maybe with the rise of deep personalization SEO will finally become Search Experience Optimization, and have users at its center instead of search engines.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!











