NEW in Keyword Explorer: See Who Ranks & How Much with Keywords by Site

Posted by randfish
For many years now, Moz’s customers and so, so many of my friends and colleagues in the SEO world have had one big feature request from our toolset: “GIVE ME KEYWORDS BY SITE!”
Today, we’re answering that long-standing request with that precise data inside Keyword Explorer:

This data is likely familiar to folks who’ve used tools like SEMRush, KeywordSpy, Spyfu, or others, and we have a few areas we think are stronger than these competitors, and a few known areas of weakness (I’ll get to both in a minute). For those who aren’t familiar with this type of data, it offers a few big, valuable solutions for marketers and SEOs of all kinds. You can:
- Get a picture of how many (and which) keywords your site is currently ranking for, in which positions, even if you haven’t been directly rank-tracking.
- See which keywords your competitors rank for as well, giving you new potential keyword targets.
- Run comparisons to see how many keywords any given set of websites share rankings for, or hold exclusively.
- Discover new keyword opportunities at the intersection of your own site’s rankings with others, or the intersection of multiple sites in your space.
- Order keywords any site ranks for by volume, by ranking position, or by difficulty
- Build lists or add to your keyword lists right from the chart showing a site’s ranking keywords
- Choose to see keywords by root domain (e.g. *.redfin.com including all subdomains), subdomain (e.g. just “www.redfin.com” or just “press.redfin.com”), or URL (e.g. just “https://www.redfin.com/blog/2017/10/migration-patterns-show-more-people-leaving-politically-blue-counties.html”)
- Export any list of ranking keywords to a CSV, along with the columns of volume, difficulty, and ranking data
My top favorite features in this new release are:
#1 – The clear, useful comparison data between sites or pages

Comparing the volume of a site’s ranking keywords is a really powerful way to show how, even when there’s a strong site in a space (like Sleepopolis in the mattress reviews world), they are often losing out in the mid-long tail of rankings, possibly because they haven’t targeted the quantity of keywords that their competitors have.
This type of crystal-clear interface (powerful enough to be used by experts, but easily understandable to anyone) really impressed me when I saw it. Bravo to Moz’s UI folks for nailing it.
#2 – The killer Venn diagram showing keyword overlaps

Aww yeah! I love this interactive venn diagram of the ranking keywords, and the ability to see the quantity of keywords for each intersection at a glance. I know I’ll be including screenshots like this in a lot of the analyses I do for friends, startups, and non-profits I help with SEO.
#3 – The accuracy & recency of the ranking, volume, & difficulty data

As you’ll see in the comparison below, Moz’s keyword universe is technically smaller than some others. But I love the trustworthiness of the data in this tool. We refresh not only rankings, but keyword volume data multiple times every month (no dig on competitors, but when volume or rankings data is out of date, it’s incredibly frustrating, and lessens the tool’s value for me). That means I can use and rely on the metrics and the keyword list — when I go to verify manually, the numbers and the rankings match. That’s huge.
Caveat: Any rankings that are personalized or geo-biased tend to have some ranking position changes or differences. If you’re doing a lot of geographically sensitive rankings research, it’s still best to use a rank tracking solution like the one in Moz Pro Campaigns (or, at an enterprise level, a tool like STAT).
How does Moz’s keyword universe stack up to the competition? We’re certainly the newest player in this particular space, but we have some advantages over the other players (and, to be fair, some drawbacks too). Moz’s Russ Jones put together this data to help compare:
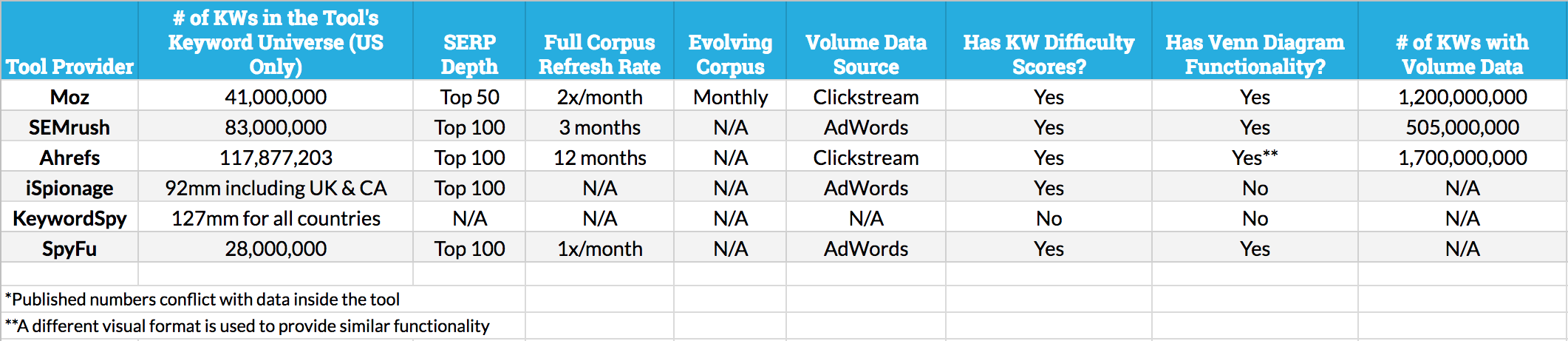
Click the image for a larger version
Obviously, we’ve made the decision to be generally smaller, but fresher, than most of our competitors. We do this because:
- A) We believe the most-trafficked keywords matter more when comparing the overlaps than getting too far into the long tail (this is particularly important because once you get into the longer tail of search demand, an unevenness in keyword representation is nearly unavoidable and can be very misleading)
- B) Accuracy matters a lot with these types of analyses, and keyword rankings data that’s more than 3–4 weeks out of date can create false impressions. It’s also very tough to do useful comparisons when some keyword rankings have been recently refreshed and others are weeks or months behind.
- C) We chose an evolving corpus that uses clickstream-fed data from Jumpshot to cycle in popular keywords and cycle out others that have lost popularity. In this fashion, we feel we can provide the truest, most representational form of the keyword universe being used by US searchers right now.
Over time, we hope to grow our corpus (so long as we can maintain accuracy and freshness, which provide the advantages above), and extend to other geographies as well.
If you’re a Moz Pro subscriber and haven’t tried out this feature yet, give it a spin. To explore keywords by site, simply enter a root domain, subdomain, or exact page into the universal search bar in Keyword Explorer. Use the drop if you need to modify your search (for example, researching a root domain as a keyword).
There’s immense value to be had here, and a wealth of powerful, accurate, timely rankings data that can help boost your SEO targeting and competitive research efforts. I’m looking forward to your comments, questions, and feedback!
Need some extra guidance? Sign up for our upcoming webinar on either Thursday, October 26th or Monday, October 30th.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
Continue reading →