Posted by rjonesx.
Here at Moz we have committed to making Link Explorer as similar to Google as possible, specifically in the way we crawl the web. I have discussed in previous articles some metrics we use to ascertain that performance, but today I wanted to spend a little bit of time talking about the impact of robots.txt and crawling the web.
Most of you are familiar with robots.txt as the method by which webmasters can direct Google and other bots to visit only certain pages on the site. Webmasters can be selective, allowing certain bots to visit some pages while denying other bots access to the same. This presents a problem for companies like Moz, Majestic, and Ahrefs: we try to crawl the web like Google, but certain websites deny access to our bots while allowing that access to Googlebot. So, why exactly does this matter?
Why does it matter?
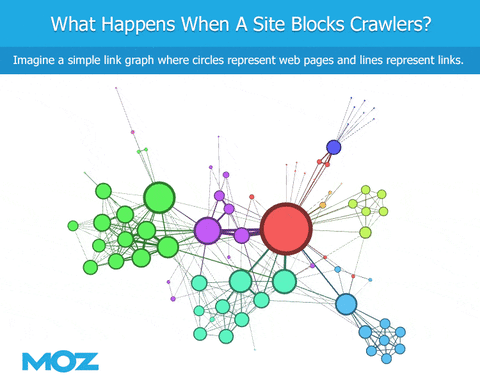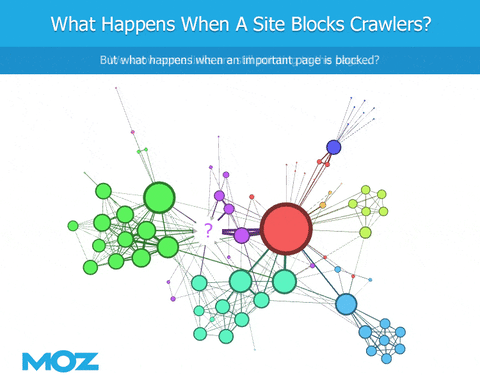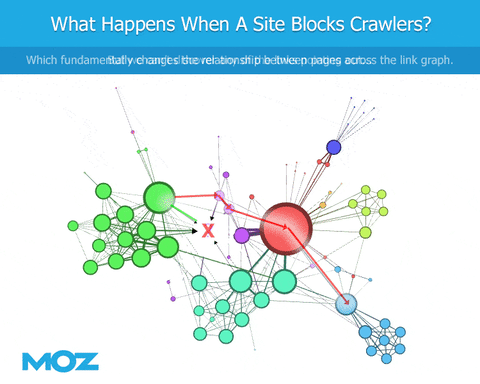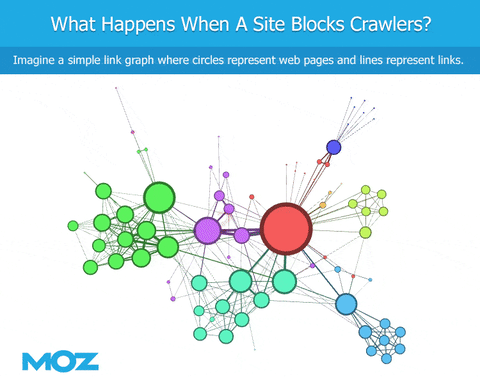
As we crawl the web, if a bot encounters a robots.txt file, they’re blocked from crawling specific content. We can see the links that point to the site, but we’re blind regarding the content of the site itself. We can’t see the outbound links from that site. This leads to an immediate deficiency in the link graph, at least in terms of being similar to Google (if Googlebot is not similarly blocked).
But that isn’t the only issue. There is a cascading failure caused by bots being blocked by robots.txt in the form of crawl prioritization. As a bot crawls the web, it discovers links and has to prioritize which links to crawl next. Let’s say Google finds 100 links and prioritizes the top 50 to crawl. However, a different bot finds those same 100 links, but is blocked by robots.txt from crawling 10 of the top 50 pages. Instead, they’re forced to crawl around those, making them choose a different 50 pages to crawl. This different set of crawled pages will return, of course, a different set of links. In this next round of crawling, Google will not only have a different set they’re allowed to crawl, the set itself will differ because they crawled different pages in the first place.
Long story short, much like the proverbial butterfly that flaps its wings eventually leading to a hurricane, small changes in robots.txt which prevent some bots and allow others ultimately leads to very different results compared to what Google actually sees.
So, how are we doing?
You know I wasn’t going to leave you hanging. Let’s do some research. Let’s analyze the top 1,000,000 websites on the Internet according to Quantcast and determine which bots are blocked, how frequently, and what impact that might have.
Methodology
The methodology is fairly straightforward.
- Download the Quantcast Top Million
- Download the robots.txt if available from all top million sites
- Parse the robots.txt to determine whether the home page and other pages are available
- Collect link data related to blocked sites
- Collect total pages on-site related to blocked sites.
- Report the differences among crawlers.
Total sites blocked
The first and easiest metric to report is the number of sites which block individual crawlers (Moz, Majestic, Ahrefs) while allowing Google. Most site that block one of the major SEO crawlers block them all. They simply formulate robots.txt to allow major search engines while blocking other bot traffic. Lower is better.

Of the sites analyzed, 27,123 blocked MJ12Bot (Majestic), 32,982 blocked Ahrefs, and 25,427 blocked Moz. This means that among the major industry crawlers, Moz is the least likely to be turned away from a site that allows Googlebot. But what does this really mean?
Total RLDs blocked
As discussed previously, one big issue with disparate robots.txt entries is that it stops the flow of PageRank. If Google can see a site, they can pass link equity from referring domains through the site’s outbound domains on to other sites. If a site is blocked by robots.txt, it’s as though the outbound lanes of traffic on all the roads going into the site are blocked. By counting all the inbound lanes of traffic, we can get an idea of the total impact on the link graph. Lower is better.

According to our research, Majestic ran into dead ends on 17,787,118 referring domains, Ahrefs on 20,072,690 and Moz on 16,598,365. Once again, Moz’s robots.txt profile was most similar to that of Google’s. But referring domains isn’t the only issue with which we should be concerned.
Total pages blocked
Most pages on the web only have internal links. Google isn’t interested in creating a link graph — they’re interested in creating a search engine. Thus, a bot designed to act like Google needs to be just as concerned about pages that only receive internal links as they are those that receive external links. Another metric we can measure is the total number of pages that are blocked by using Google’s site: query to estimate the number of pages Google has access to that a different crawler does not. So, how do the competing industry crawlers perform? Lower is better.

Once again, Moz shines on this metric. It’s not just that Moz is blocked by fewer sites— Moz is blocked by less important and smaller sites. Majestic misses the opportunity to crawl 675,381,982 pages, Ahrefs misses 732,871,714 and Moz misses 658,015,885. There’s almost an 80 million-page difference between Ahrefs and Moz just in the top million sites on the web.
Unique sites blocked
Most of the robots.txt disallows facing Moz, Majestic, and Ahrefs are simply blanket blocks of all bots that don’t represent major search engines. However, we can isolate the times when specific bots are named deliberately for exclusion while competitors remain. For example, how many times is Moz blocked while Ahrefs and Majestic are allowed? Which bot is singled out the most? Lower is better.

Ahrefs is singled out by 1201 sites, Majestic by 7152 and Moz by 904. It is understandable that Majestic has been singled out, given that they have been operating a very large link index for many years, a decade or more. It took Moz 10 years to accumulate 904 individual robots.txt blocks, and took Ahrefs 7 years to accumulate 1204. But let me give some examples of why this is important.
If you care about links from name.com, hypermart.net, or eclipse.org, you can’t rely solely on Majestic.
If you care about links from popsugar.com, dict.cc, or bookcrossing.com, you can’t rely solely on Moz.
If you care about links from dailymail.co.uk, patch.com, or getty.edu, you can’t rely solely on Ahrefs.
And regardless of what you do or which provider you use, you can’t links from yelp.com, who.int, or findarticles.com.
Conclusions
While Moz’s crawler DotBot clearly enjoys the closest robots.txt profile to Google among the three major link indexes, there’s still a lot of work to be done. We work very hard on crawler politeness to ensure that we’re not a burden to webmasters, which allows us to crawl the web in a manner more like Google. We will continue to work more to improve our performance across the web and bring to you the best backlink index possible.
Thanks to Dejan SEO for the beautiful link graph used in the header image and Mapt for the initial image used in the diagrams.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!